序
在 Android 中,IDE 偶尔会提到我们应该使用 SparseArray 替换掉 HashMap,其根本原因就在于 SparseArray 相比较 HashMap 会更省内存。
具体理解 SparseArray 呢?记住三句话就好了。
> SparseArray 内部使用双数组,分别存储 Key 和 Value,Key 是 int[],用于查找 Value 对应的 Index,来定位数据在 Value 中的位置。
> 使用二分查找来定位 Key 数组中对应值的位置,所以 Key 数组是有序的。
> 使用数组就要面临删除数据时数据搬移的问题,所以引入了 DELETE 标记。
双数组
SparseArray 内部使用双数组,分别存储 Key 和 Value,Key 是 int[],用于查找 Value 对应的 Index,来定位数据在 Value 中的位置。
在 SparseArray 内部,采用两个数组来存放数据,它们是一一对应的关系。
public class SparseArray<E> implements Cloneable {
private int[] mKeys;
private Object[] mValues;
private int mSize;
}
mValue 数组是为了存储数据的索引,它和 mKey 数组的关系是一一对应的,我们通过 key 的值,就可以定位出它在 mKey 数组中的 index,进而可以操作 mValue 数组中对应的位置。
因为是一一对应的关系,所有对数据的操作,都需要对这两个数据进行操作。第一句话就是为了对 SparseArray 数据是如何存储的,有一个基本的认识。
二分查找
既然是使用数组这种顺序表,在查找的时候通常需要从前向后遍历数组,这时的时间复杂度就是 O(n),这明显不是 SparseArray 想要的。
在 SparseArray 中,采用二分查找算法,来快速通过 key 定位出它在 mKey 数组中的位置,二分查找的实现,在 ContainerHelpers.binarySearch() 中。正因为使用了二分查找, SparseArray 的查找操作,时间复杂度可以做到 O(logn)。
再看 SparseArray 的源码,所有和 key 相关的操作,第一步都是通过二分查找,定位出它的 index,再进行后续的处理,例如 get() 的实现。
public E get(int key, E valueIfKeyNotFound) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i < 0 || mValues[i] == DELETED) {
return valueIfKeyNotFound;
} else {
return (E) mValues[i];
}
}
先忽略其中的 DELETE 标记的逻辑,后面会讲到。
binarySearch() 中会通过 key 查找对应的 index,如果查询不到,它会返回一个负数 i,注意这个 i 是有意义的,i 的相反数,就是 key 在 mKey 数组中,比较合适的位置(index)。
什么叫比较合适的位置?
就是虽然这个 key 没有在 mKey 数组中找到,但是如果把 key 插入到 mKey 数组的第 i 个位置上,mKey 数组依然是有序的。
我们知道,二分查找的前提条件,就是必须是针对有序并且支持下标随机访问的数据结构,所以它在执行插入操作的时候,必须保证 mKey 数据中的数据有序。也正因为如此,mKey 数组是一个基本类型的 int 数组,天然有序并且大小比对也简单。
我们看看 put() 方法的实现就清楚了。
public void put(int key, E value) {
int i = ContainerHelpers.binarySearch(mKeys, mSize, key);
if (i >= 0) {
mValues[i] = value;
} else {
i = ~i;
if (i < mSize && mValues[i] == DELETED) {
mKeys[i] = key;
mValues[i] = value;
return;
}
if (mGarbage && mSize >= mKeys.length) {
gc();
// Search again because indices may have changed.
i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);
}
mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);
mValues = GrowingArrayUtils.insert(mValues, mSize, i, value);
mSize++;
}
}
数组的插入,一定会伴随着数据的搬移。
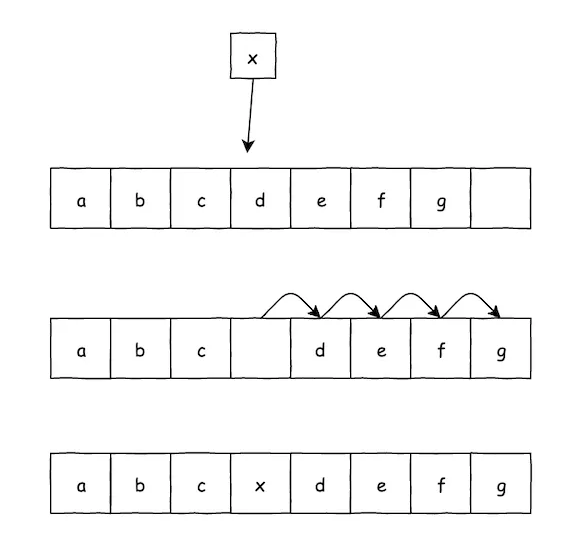
而在 put() 方法中,也会用到二分查找定位 key 的 index,我们主要关注其中的 GrowingArrayUtils.insert() 方法。
在这个 insert() 方法中,完成两个任务:
> 将数据插入到指定数组对应的位置上。
> 如果发现数组空间不够了,就生成一个更大的新数组,将数组通过复制的方法,动态扩容后搬移到新数组中,并返回新数组。
这些高级集合类,和基本数据结构有一个最显著的区别,就是它支持动态扩容,而 SparseArray 动态扩容的实现代码,在 GrowingArrayUtils 的 insert() 方法中,其原理就是一次动态复制来扩容。
扩容的逻辑也很简单,就是依据当前的 Size 动态放大,Size 在 4 以上时,每次扩容 2 倍。具体算法在 GrowingArrayUtils 的 growSize() 方法中。
<span class="">public static int growSize(int currentSize) </span>{
<span class="">return</span> currentSize <= <span class="">4</span> ? <span class="">8</span> : currentSize * <span class="">2</span>;
}
第二句话,说明了 SparseArray 内部使用二分查找,在 mKey 数组中定位 key 的位置。又因为需要支持二分查找,所以 mKey 数组内存储的数据,必须是有序的。所以在 put() 操作的时候,就需要通过数组插入的方式,来保证数据的有序。
又因为使用了数组结构,在数据空间不够时,还需要采取动态扩容的方式,采用新旧数组复制的方式,增大数组的空间,这部分操作都封装在 GrowingArrayUtils 的 insert() 方法中。
DELETE 标记
使用数组就要面临删除数据时数据搬移的问题,所以引入了 DELETE 标记。
SparseArray 用到了「数组」结构,在插入的时候为了给新数据腾位置,需要执行一个时间复杂度度为 O(n) 的搬移操作,这是无法避免的。
但是删除操作其实是有优化空间的。对数组的删除,如果不做数据搬移,数组中必然存在数据空洞。
SparseArray 对删除操作的优化,引入 DELETE 标记,以此来减少在删除数据时对数据的搬运次数,以此达到在删除时做到 O(1) 的时间复杂度。
而在插入的时候,遇到 DELETE 标识,表示当前数据已经被删除掉了。
这样优化的删除的同时,对插入操作也起到了一定的优化,就像前面展示的 put()代码实现中,如果二分查找的结果,发现对应文字的 value 为 DELETE,则直接替换,减少了一次插入带来的数组的数据搬运。
注意 DELETE 标识是在 mValue 数组中存储的,mKey 中依然存储着它上一次对应数据的 key 值。
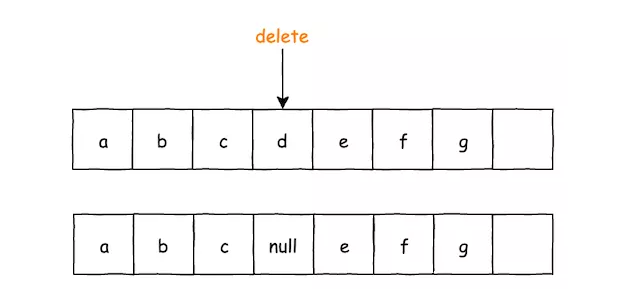
但是引入 DELETE 标识就会有个问题,虽然数据被删除了,但是它依然在数组中占有位置空间,也就是它会影响到一些操作,例如在调用 size() 方法的时候,肯定是想知道真实数据的数量,而不应该包含 DELETE 标识的数据量。又例如在 put() 操作时发现数组空间不够,但是数组内存在 DELETE 标识,此时应该做的是去清理 DELETE 标识,而不是去扩容数组。
引入 DELETE 让 delete() 操作可以做到 O(1) 的时间复杂度,但是也带来了问题,这就引入了 SparseArray 的 gc() 机制。
GC 我相信大家都比较熟悉,它在 JVM 里代表对内存的回收机制,而在 SparseArray 中,它标识了对 DELETE 标识的回收。
在一些必要的条件下,会触发 gc() 逻辑,来清理双数组中的 DELETE 标识。
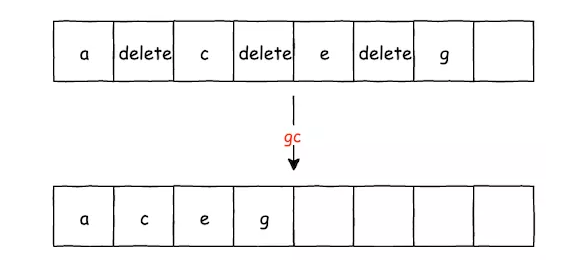
gc() 方法中,通过一次循环,就可以完成 DELETE 标识的清除,在 gc() 方法中,用了一个布尔类型的 mGarbage 属性,来记录当前 mValue 中,是否存在 DELETE 标识,这是判定是否需要 GC 的依据。。
gc() 会有一次循环,这是 O(n) 的时间复杂度,那什么时候执行 gc() 也是有讲究的。
如果你在 SparseArray 文件中搜索 gc() 方法的调用,你会发现有很多地方都用到了 gc() 方法。原则上,有两类操作可能会触发到 gc() 逻辑,所有和 size 相关的操作以及和数组扩容相关的操作。这很好理解,通过 index 获取数据,必须保证 size 的准确,所以如果有 DELETE 标识,必须执行 gc(),扩容时也是,存在 DELETE 标识说明还有剩余的空间,无需进行扩容。
到这里第三句话也理清楚了,引入 DELETE 标识是为了减少删除数据时数据的搬移次数,而这必然带来了数组的「空洞」,为了解决这个问题,又需要在适当的时候触发 GC 操作,来回收 DELETE 标识。
SparseArray 的一些变体
SparseArray 还存在一些变体类,用于处理不同的情况。
SparseBooleanArray
SparseIntArray
SparseLongArray
LongSparseArray
LongSparseLongArray
原文链接:承香墨影