前言
看看时间也快10月了,一个offer都没有,这样不行啊,天天看海投网上宣讲会信息,可是在2300+条信息里面找出符合自己的,想想就觉得崩溃,所以有了这个爬虫。也算的上是具有"程序猿特色"的求职之路。
目标分析
首先看看目标网址:海投网武汉地区宣讲会
目标分析:这里我使用的是火狐浏览器自带的调试工具,当然你也可以使用Firebug用来方便查看目标源码。如下图
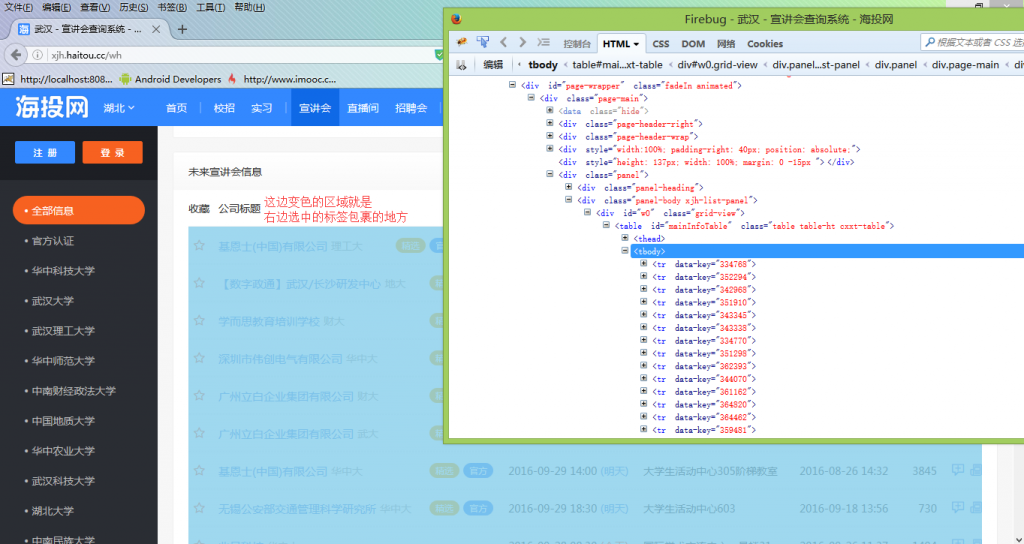
我们可以看到,整个宣讲会是一个<table></table>,其中<tbody>下的每一个<tr>标签都包裹着一条宣讲会信息。他下面的<td>标签则包含着我们需要的内容。如下图。
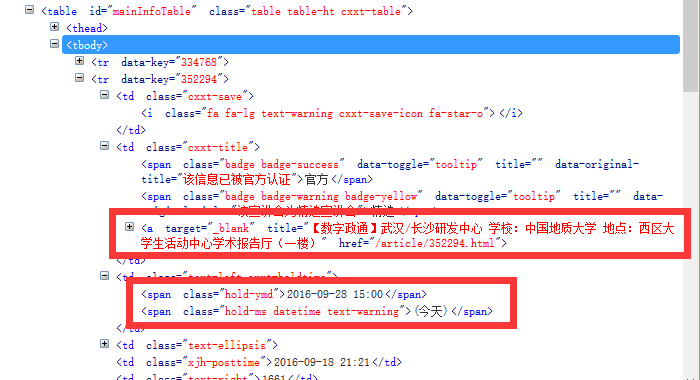
分析结果:只需要获取页面上<table></table>下的<tr>中的<td>标签中的内容,就是我们需要的信息。
获取到所有页面
获取下一页和上一页
我们先随意切换上下页,第二页的url为:http://xjh.haitou.cc/wh/page-2 ,第3页的url为:http://xjh.haitou.cc/wh/page-3 ,可以很清楚的看到,页码的切换其实就是page-页码即可。
获取到最后一页
经过上面的分析我们可以知道了怎么获取到上下页,下面我来介绍下如何获取到最后一页。
首先看看非最后一页的下一页按钮
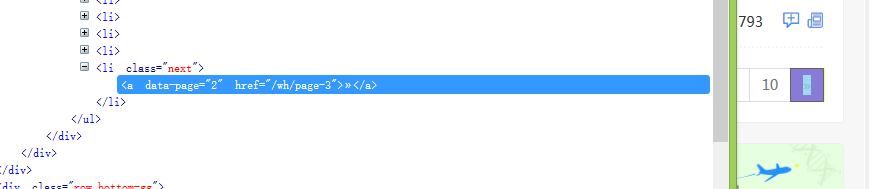
再来看看最后一页的下一页按钮

可以看到,当页面中存在li元素 class为next的时候,说明有下一页,当到达最后一页以后,li class为disable。这样我们就可以知道如何不停获取下一页了。
当我们获取到所有的宣讲会信息以后就可以直接获取这个宣讲会详细的信息了,然后在宣讲会中判断是否存在自己希望出现的字符即可。
实际编码
整个编码总的来说分为两部分,一部分为获取宣讲会信息,这一部分在上面以及介绍的很清楚了,另一部分则是访问所有获取到的宣讲会信息,判断处理,保存等。
在程序中维护一个任务队列,开启一个辅助线程获取宣讲会信息,将封装好的宣讲会信息提交到任务队列,然后使用工作线程处理任务队列中的任务。这里为了简便,直接使用了线程池。解析html使用了Jsoup库,关于Jsoup的用法请查看:Jsoup中文帮助文档
首先将宣讲会信息封装起来。
public class Task {
// 公司详情url
public String url;
// 公司名称
public String name;
// 学校名称
public String school;
// 学校具体地点
public String addr;
// 宣讲会时间
public String time;
public Task(String url, String name, String school, String addr, String time) {
this.url = url;
this.name = name;
this.school = school;
this.addr = addr;
this.time = time;
}
@Override
public String toString() {
return String.format("公司:%s\n详情地址:%s\n学校:%s\n具体地点:%s\n时间:%s\n", name,
url, school, addr, time);
}
}
然后式辅助线程,主要用于解析主界面
/**
* 辅助线程,启动以后解析主界面,然后将任务提交到消息队列
*/
public class HelpThread extends Thread {
public String url = "http://xjh.haitou.cc/wh/page-";
public String baseUrl = "http://xjh.haitou.cc";
public int count = 0;
private Queue mQueue;
public HelpThread(Queue queue) {
this.mQueue = queue;
}
@Override
public void run() {
super.run();
int nowPage = 1;
// 一直循环,直到没有下一页
while (prasePage(nowPage)) {
nowPage++;
}
System.out.println("搜索完毕,搜索总数:" + count);
mQueue.shutdown();
}
private boolean prasePage(int page) {
// 不使用Jousp.connect()方法,因为可能出现乱码
Document doc = null;
try {
doc = Jsoup.parse(new URL(url + page).openStream(), "utf-8",
baseUrl);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 查找table下的tr
Elements trs = doc.select(".table tr");
// 遍历所有tr
for (Element tr : trs) {
Task task = initTask(tr);
if (task != null) {
mQueue.addTask(task);
count++;
}
}
//System.out.println("搜索页码:" + page + "count = " + count);
return hasNextPage(doc);
}
/**
* 返回是否有下一页
*/
private boolean hasNextPage(Document doc) {
boolean hasNext = doc.select("li.next").size() > 0;
return hasNext;
}
private Task initTask(Element tr) {
// 找出学校 公司 宣讲会位置 公司详情地址
Elements detail = tr.select("td.cxxt-title");
Elements result = detail.select("a");
if (result.size() <= 0)
return null;
// 绝对地址
String url = result.attr("abs:href");
String title = result.attr("title");
String[] split = title.split("\\s");
// 找出时间
String time = tr.select("span.hold-ymd").text();
return new Task(url, split[0], split[1].replace(" 学校:", ""),
split[2].replace("地点:", ""),time);
}
}
工作线程
/**
* 工作线程 消息队列取出的消息的执行者
*/
public class WorkThread extends Thread {
private Task mTask;
public static String baseUrl = "http://xjh.haitou.cc";
public static String target = ".*(android|Android|安卓|移动开发).*";
// public static String target = ".*(前端设计|web前端|前端工程师|网页设计|前端).*";
public WorkThread(Task mTask) {
this.mTask = mTask;
}
@Override
public void run() {
try {
Document doc = Jsoup.parse(new URL(mTask.url).openStream(),
"utf-8", baseUrl);
String context = doc.select("div.panel-body").text();
if (context.matches(target)) {
FileOutputUtil.outputTask(mTask, context);
System.out.println("发现+1");
}
} catch (IOException e) {
FileOutputUtil.outputError(mTask.toString() + "" + e.getMessage()
+ "\n---------end---------\n");
}
}
}
最后附上一张效果图
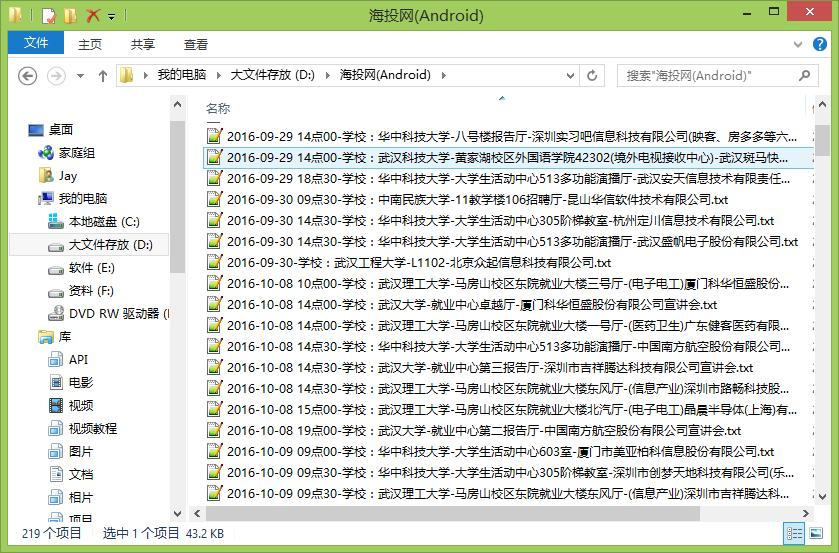
吊了吊了。word 哥
[…] 从爬虫开始找工作 […]
由于本篇文章不停的被恶意评论,所以关闭本篇博客的评论。